앞선 2편에서는 각 가사에 대해 5개의 핵심 키워드를 추출하고, 이를 학습 데이터셋으로 정리하는 과정을 다뤘습니다.
이번 글에서는 이 데이터셋을 활용하여 QLoRA 방식으로 소형 LLM을 튜닝하는 과정을 소개합니다.
📦 모델 준비
모델은 로컬 환경에서 동작하도록 Hugging Face의 **gemma-2-2b**를 다운로드 후 사용했습니다.
model_path = "./hug_model/gemma-2-2b/"
오프라인 환경에서도 모든 단계가 작동하도록 구성하는 것이 목표였기 때문에,
모델 로드부터 데이터 처리, 학습까지 인터넷 연결 없이 수행할 수 있도록 세팅했습니다.
📊 데이터 불러오기 및 전처리
전처리와 키워드 추출이 완료된 CSV 파일(keyword_lyric_train2.csv)을 로드하여 Hugging Face Dataset 형태로 변환했습니다.
import pandas as pd
from datasets import Dataset
# CSV 로드
df = pd.read_csv("keyword_lyric_train2.csv")
# HF Dataset 변환
dataset = Dataset.from_pandas(df)
# Train/Validation Split
dataset = dataset.train_test_split(test_size=0.1, seed=42)
📝 토크나이징
각 가사의 5개 키워드를 하나의 문장으로 합쳐 “질문” 역할을 하고,
해당 가사를 “답변”으로 하여 학습 텍스트를 구성했습니다.
def tokenize(example):
# 키워드 모으기
keywords = [example.get(f"key{i}", "") for i in range(1, 6)]
keywords = [kw.strip() for kw in keywords if kw and kw.strip() != ""]
# 질문 = 키워드 기반 가사 작성 지시
question_text = "다음 키워드를 포함하는 가사를 작성하세요: " + ", ".join(keywords)
# 답변 = 가사
answer_text = example["Lyric"]
# 학습용 텍스트
text = f"질문: {question_text}\n답변: {answer_text}"
return tokenizer(text, truncation=True, padding="max_length", max_length=512)
# 토크나이즈 적용
tokenized_dataset = dataset.map(tokenize, batched=False)
⚙️ 학습 설정 (QLoRA)
GPU 메모리 효율을 위해 QLoRA 세팅을 적용했습니다.
per_device_train_batch_size=1에 gradient accumulation을 적용하여 RTX 3090에서도 원활히 학습 가능했습니다.
training_args = TrainingArguments(
output_dir="./gemma2b-qlora",
per_device_train_batch_size=1,
gradient_accumulation_steps=16,
warmup_steps=100,
learning_rate=2e-4,
num_train_epochs=3,
logging_steps=50,
save_strategy="epoch",
fp16=True,
optim="paged_adamw_8bit",
report_to="none"
)
🚀 학습 실행
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
tokenizer=tokenizer,
data_collator=data_collator
)
trainer.train()
학습이 완료된 후, 어댑터를 저장하고 테스트를 진행했습니다.
학습은 RTX 3090 환경에서 batch size=1, gradient accumulation=16 설정으로 진행되었으며, 약 3시간이 소요되었습니다.
📊 학습 과정 분석

1. 초기 급격한 하락
- Step 0 ~ 100 구간에서 Loss가 2.7 → 2.4로 빠르게 감소했습니다.
- 이는 모델이 초기 단계에서 데이터의 전반적인 패턴을 빠르게 파악하고 있음을 보여줍니다.
- QLoRA 튜닝에서 흔히 나타나는 정상적인 현상입니다.
2. 점진적 감소
- Step 100 이후부터는 완만한 하락세를 보이며 2.1 근처로 수렴했습니다.
- 큰 폭의 변화는 없지만, 꾸준히 개선되는 흐름은 학습률과 배치 설정이 적절하다는 의미입니다.
3. 중간 변동(진동)
- Step 200 ~ 1000 구간에서 Loss 값이 다소 오르내리는 현상이 관찰되었습니다.
- 이는 미니배치 구성과 데이터 난이도 차이로 인한 자연스러운 변동이며,
전체적인 추세선은 여전히 하락 방향을 유지합니다. - 진폭이 크지 않아 학습률 조정이 필요해 보이지 않습니다.
4. 마무리 구간
- Step 1000 이후에는 Loss가 약 2.1 수준에서 평탄화되었습니다.
- 이는 모델이 주어진 데이터에 대해 충분히 수렴했음을 의미합니다.
🎤 테스트 결과
테스트 키워드:
love, hot, street, girl, free
생성된 가사(원문):
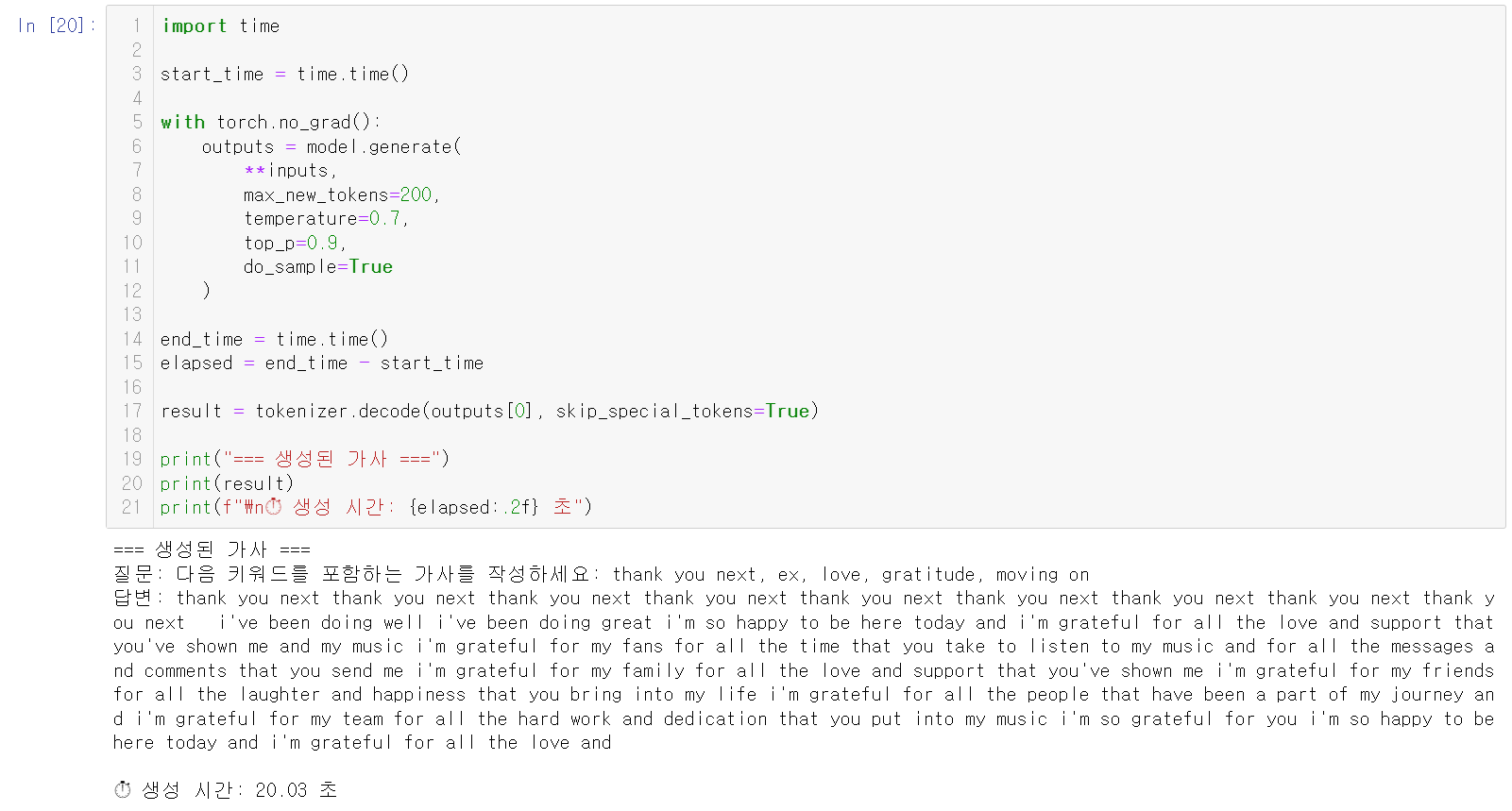
가사로 쓰기 좋게 정리한 형태:
"""
baby
i've been feeling love lately
i've been feeling love lately
i've been feeling love lately
i've been feeling love lately
pre when i'm out on the streets out on the streets
i'm feeling love lately
i'm feeling love lately
i'm feeling love lately
when i'm out on the streets out on the streets
i'm feeling love lately
i'm feeling love lately
i'm feeling love lately
"""
🎵 작사 LLM의 특성
일반적인 대화형 LLM과 달리, 작사 LLM은 반복되는 단어나 문장, 심지어 앞뒤 문맥이 조금 어긋나더라도
리듬·멜로디와 결합했을 때 훅(hook)처럼 들릴 수 있습니다.
따라서 이런 반복 구조는 오히려 가사의 자연스러운 특성으로 받아들일 수 있습니다.
🔜 다음 이야기
다음 편에서는 이렇게 학습된 모델을 Suno AI와 결합하여 실제 음악 트랙으로 변환하는 과정을 다룰 예정입니다.
작사 LLM이 생성한 가사가 멜로디와 만나 어떻게 곡으로 완성되는지 살펴봅니다.
📌 4편 예고: "작사 LLM 제작 – 4. Suno AI와의 결합으로 곡 완성하기"
'LLM' 카테고리의 다른 글
| 작사 LLM 제작 – 4. Suno AI와의 결합으로 곡 완성하기 (4) | 2025.08.09 |
|---|---|
| 작사 LLM 제작 - 2. 키워드 추출과 데이터셋 구축 (4) | 2025.08.08 |
| 작사 LLM 제작 - 1. 데이터 전처리 (4) | 2025.08.08 |