우선 파이캐럿을 설치할때 충돌이 있을 수 있으니, 아래의 블로그를 참고해서 가상환경을 새로 만들고, 파이캐럿 설치 및 주피터 노트북 커널 연결까지 완료해서 환경 구축을 완료 한다.
https://31weeks.tistory.com/314
아나콘다 - 가상환경 구성 및 주피터 노트북 커널 연결
1. 가상환경 생성 conda create -n test01 python=3.10.9 : 파이썬 버전 3.10.9로 가상환경 'test01'생성 2. 가상환경 들어가기 conda activate test01 3. 가상환경 들어가서 주피터 설치 pip install jupyter notebook 4. 커널 연
31weeks.com
https://31weeks.tistory.com/315
아나콘다 - 파이캐럿 설치
PyCaret은 기계 학습 워크플로를 자동화하는 Python의 오픈 소스 로우 코드 기계 학습 라이브러리이지만, 설치할때 다른 라이브러리와 충돌이 있을 수 있으므로 타 라이브러리 보다 제일 먼저 설치
31weeks.com
환경 구축이 완료되면 이전에 포스팅했던 내용을 참고해서 비트코인의 가격데이터를 크롤링 하거나, csv 파일을 다운받아서 머신러닝에 사용한다.
https://skydance.tistory.com/53
[파이썬] 업비트 코인별 가격 데이터 - 크롤링
코인의 가격 데이터를 크롤링 해서 csv 파일로 저장해 놓으면, 자동매매를 하기 위해서 각종 지표들을 계산할 때 마다 매번 API를 호출하지 않아도 된다. 따라서 장기간의 데이터로 계산을 해야되
skydance.tistory.com
아래의 코드를 실행해서 비트코인 가격에 대한 csv 파일을 불러오고, 데이터를 학습용 데이터와 테스트용 데이터로 나눈다.
| import pandas as pd import random import os import numpy as np from pycaret.regression import * def seed_everything(seed): random.seed(seed) os.environ['PYTHONHASHSEED'] = str(seed) np.random.seed(seed) seed_everything(42) # Seed 고정 df = pd.read_csv('KRW-BTC.csv') train_df = df[:int(len(df)*0.8)] test_df = df[int(len(df)*0.8):] train_x = train_df.drop(['close'], axis = 1) train_y = train_df['close'] test_x = test_df.drop(['close'], axis = 1) test_y = test_df['close'] |
데이터 처리가 완료되면 아래의 코드를 실행해서 파이캐럿으로 해당 데이터에 적합한 모델을 비교하고, 상위모델 3개를 선정하여 예측을 진행한다.
| clf = setup(train_x, target=train_y, session_id=123) |

| best_model = compare_models(n_select = 3) |
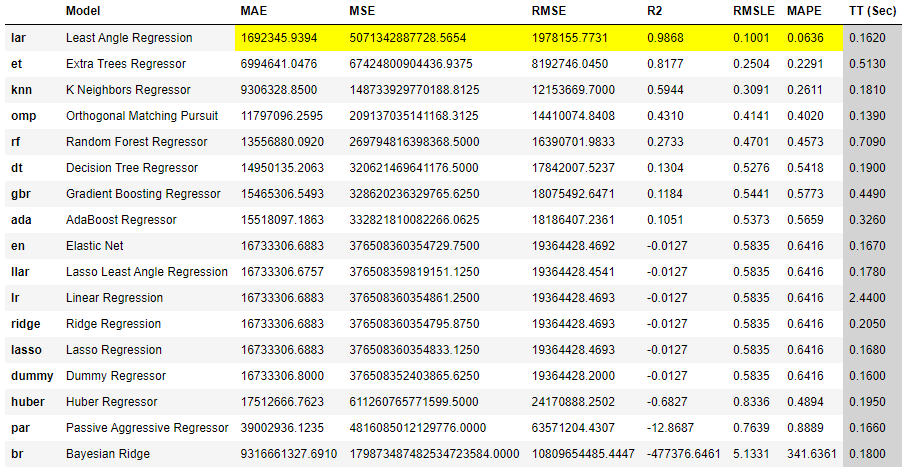
| b1 = best_model[0] b2 = best_model[1] b3 = best_model[2] predictions_1 = predict_model(b1,data=test_x) predictions_2 = predict_model(b2,data=test_x) predictions_3 = predict_model(b3,data=test_x) |
예측이 완료되면 아래의 코드로 시각화 해서 예측값과 실측값을 비교해 보는데, 1 ~ 3위 사이의 정확도 차이가 확연히 나는 것을 볼수 있다. 특히, 가장 높은 정확도를 보여준 Least Angle Regression(LAR) 모델은 얼핏보기에 아주 높은 정확도로 가격을 예측한 것으로 보이는데, 여기에는 아주 큰 모순이 있다.
| import matplotlib.pyplot as plt # 그래프 그리기 plt.figure(figsize=(10, 6)) # 그래프 크기 설정 plt.plot(test_y, label='Actual Close', marker='.') # test_y 데이터 그래프로 표시 plt.plot(predictions_1['prediction_label'], label='Predicted Close', marker='.') # pred_y 데이터 그래프로 표시 # 그래프 제목과 레이블 설정 plt.title('Actual vs. Predicted Close Prices') plt.xlabel('Time') plt.ylabel('Close Price') # 범례 표시 plt.legend() # 그래프 표시 plt.show() |
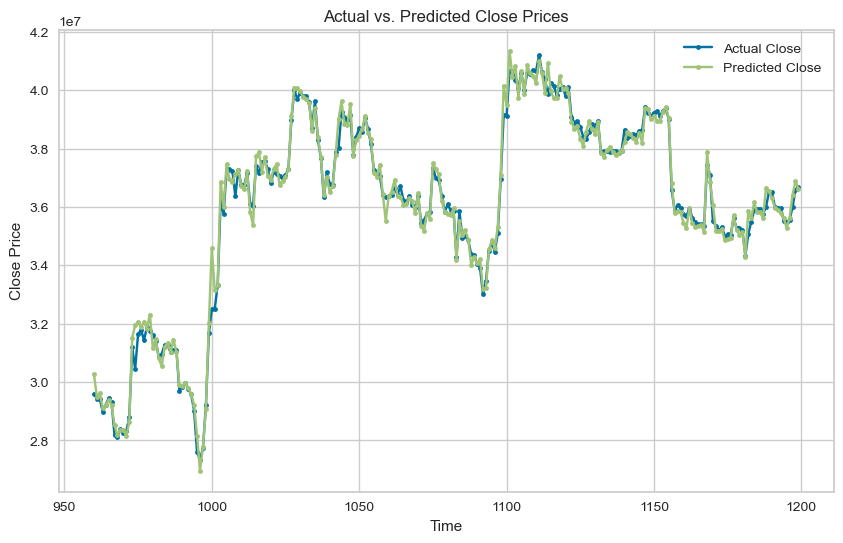
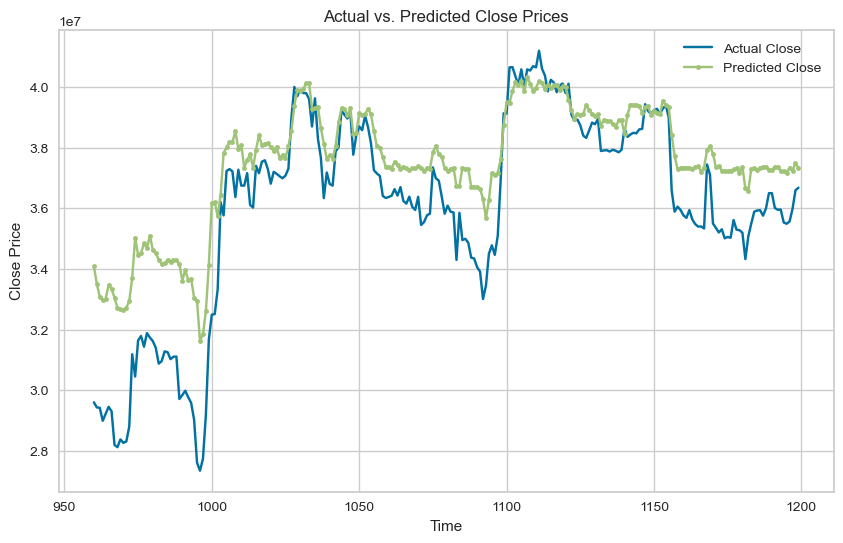
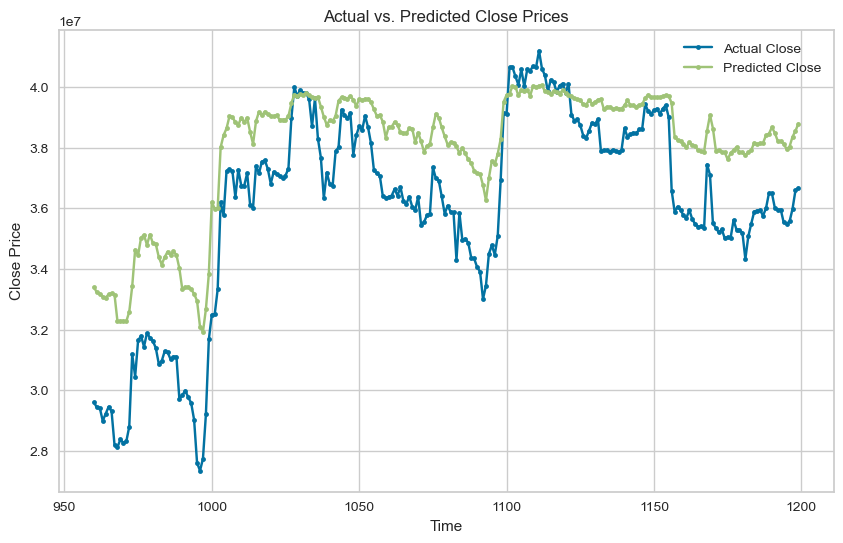
위의 코드는 시가(Open), 고가(High), 저가(Low), 거래량(Volume), 시총(Value)을 바탕으로 종가(Close)를 예측하는 코드다. 바로 여기서 모순이 발생하는데, 24시간 돌아가는 코인 시장은 한국시간 기준으로 매일 아침 9시(런던 기준 0시)에 망이 마감하고 다시 시작하고 이때를 기준으로 종가가 기록된다. 또한, 이때 기록된 종가를 기준으로 시총이 결정되고, 저가와 고가, 거래량이 확정된다.
따라서, 결과적으로 종가가 확정되고 나서야 그 종가를 예측할 수 있게 되는 것이다. 우리는 1일 단위로 기록된 이 데이터에서 '가격 예측'이 되려면, 최소한 내일 이후의 가격을 예측해야 하므로, 종가(close) 칼럼을 shift 등의 전처리가 필요하다.
'Finance > 업비트' 카테고리의 다른 글
| [파이썬] 업비트 비트코인 머신러닝 가격예측 2 (3) | 2024.01.24 |
|---|---|
| [파이썬] 업비트 코인별 가격 데이터 - 크롤링 (1) | 2023.09.30 |
| [파이썬] 업비트 티커 리스트 - 상장 400일 이하 제거 (1) | 2023.05.20 |
| [파이썬] 업비트 티커 리스트 - 크롤링 (0) | 2023.05.17 |
| [파이썬] 업비트 지표 구하기 - RSI(상대강도지수) (2) | 2023.03.06 |